6. SAE
Recentemente, a linha de pesquisa de utilizar Autoencoders Esparsos (ou Sparse Autoencoders) tem sido cada vez mais explorada na área de interpretabilidade de modelos como uma tentativa de contornar o problema da superposição. A proposta é utilizar esses modelos para gerar features aprendidas que ofereçam uma unidade mais monossêmico de análise que os neurônios do modelo.
Definição (autoencoder). Tipo de rede neural cujo objetivo é aprender representações eficientes de maneira não supervisionada. É composto por um encoder, que gera a representação latente (que, em geral, possui dimensão menor que o input), e um decoder, responsável por realizar uma reconstrução da representação do espaço latente de volta para o espaço do input.
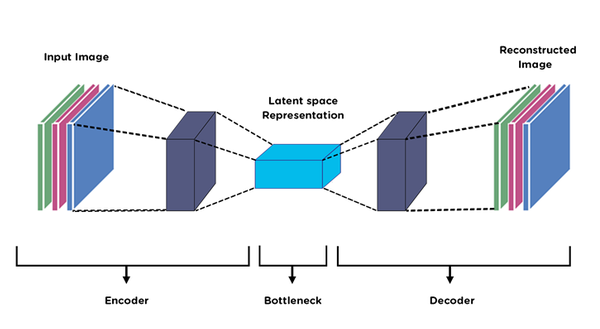
Definição (autoencoder esparso (SAE)). Autoencoder que aprende representações esparsas em um espaço de dimensionalidade maior do que as entradas.
Observações:
- A função de perda de um SAE normalmente é composto pela soma de uma perda de reconstrução (norma 2 entre a entrada e a saída) e uma penalidade de esparsidade (norma 1 da representação latente).
- A ideia trazida recentemente em artigos buscando contornar a superposição de features 1 2 é utilizar SAEs para recuperar features sobrepostas, mapeando o espaço de features para um espaço latente esparso e de maior dimensão, permitindo a extração monossêmica de features interpretáveis.
- Esse autoencoder é treinado em camadas internas de modelos de linguagem, decompondo as ativações em mais features do que a quantidade de neurônios existentes.
Teoria de que redes neurais pequenas exploram a esparsidade de features e propriedade de espaços de alta dimensão para simular aproximadamente redes muito maiores e mais esparsas.
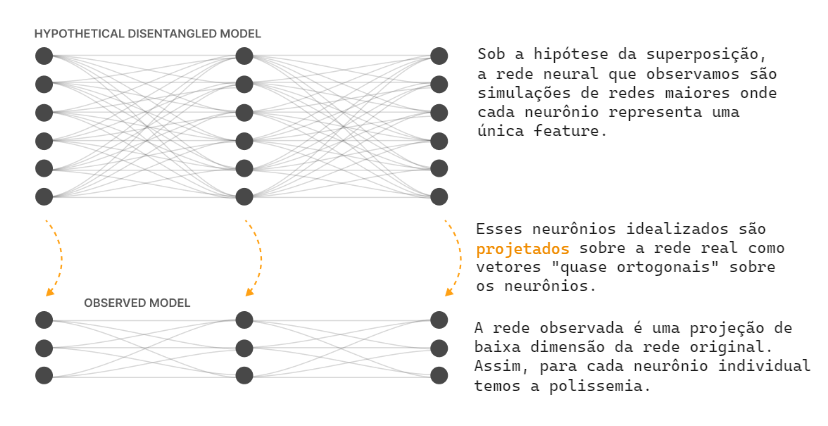
A proposta de utilizar SAEs para resolver a superposição compreende que o espaço latente obtido após treinamento em camadas internas da MLP de Transformers realiza a projeção inversa, nos levando de volta ao modelo hipotético em que não há superposição.
O uso de SAEs para interpretabilidade tem crescido em tempos recentes, principalmente desde a publicação de “Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet” pela Anthropic.
Esse artigo estabelece o primeiro sucesso em utilizar SAEs para criar um espaço de features interpretáveis e monossêmicas em um modelo de linguagem grande, já que até então todos os avanços haviam sido feitos em toy models.
Além de descobrir um espaço de milhões de features, o artigo também apresenta resultados qualitativos da alteração de features especificas, aumentando e diminuindo valores de ativações correspondentes para observar comportamentos do modelo.

Cunningham, H., Ewart, A., Riggs, L., Huben, R., & Sharkey, L. (2023). Sparse Autoencoders Find Highly Interpretable Features in Language Models. https://arxiv.org/abs/2309.08600 ↩︎
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Hatfield-Dodds, Z., Tamkin, A., Nguyen, K., … Olah, C. (2023). Towards Monosemanticity: Decomposing Language Models With Dictionary Learning. Transformer Circuits Thread. ↩︎